
December 2021 Issue
Research Highlights
Educational measurement
Modelling performance assessment
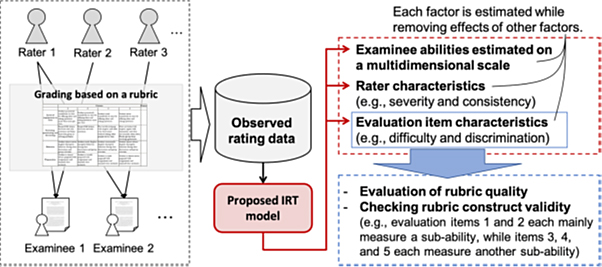
Performance assessment of a practical task carried out by an examinee is typically done by human raters awarding scores for different parts of the task. Often, a so-called scoring rubric is used for this purpose, listing the various parts and descriptions of the performance scores associated with them. There are some inherent shortcomings to this procedure, however, including the characteristics of the rubric’s evaluation items and the raters’ behaviour — one rater may score differently than another. Now, Masaki Uto from the University of Electro-Communications has developed a new model that takes into account the specifics of a rubric’s evaluation items and the raters.
The approach followed by Uto relies on models developed in a theoretical framework known as item response theory. It is based on a formula giving the probability Pijkr that examinee j gets score k for evaluation item i by rater r. The formula typically contains parameters such as the difficulty (βi) for the evalution item, the latent ability of the examinee (θj) and the severity of the rater (βr). The idea is then that, by fitting the formula to an existing dataset with known score outcomes, good values of the parameters (like βi, θj and βr) can be obtained. Yet, this description is almost always too simplistic to result in good results, however.
One improvement lies in incorporating the notion of ability dimensions — an abstract representation of an examinee having different ability ‘spheres’. Uto’s model combines ability dimensions with rater characteristics, which signifies a step forward in item response theory modelling.
Apart from providing a more realistic description of performance assessment with a rubric and raters, the model can also help to check the quality of the rubric’s evaluation items, as well as providing insights into what exactly each ability dimension measures.
Uto tested the probability formula by first simulating a large number of data sets, with randomly generated parameters. Then, the data sets were fitted to the formula, resulting in estimated parameters. Good agreement between the true and the fitted parameters was obtained, showing that the model works well. Moreover, specific simulations showed that the inclusion of rater characteristics led to improved examinee ability accuracy.
The model was also tested in actual data experiments, with 134 Japanese university students performing an essay-writing task requiring no preliminary knowledge. One conclusion was that, for this case, a two-dimensionality assumption worked better than a one-dimensional ability. A further finding was that the inclusion of rater characteristics indeed improved model fitting.
Uto plans to further test the model’s effectiveness using various and more massive datasets, and to, quoting the researcher, “extend the proposed model to four-way data consisting of examinees × raters × evaluation items × performance tasks because practical tests often include several tasks.”
References
