December 2016 Issue
Research Highlights
Speech signal processing: Enhancing voice conversion models
Altering a person's voice so that it sounds like another person is a useful technique for use in security and privacy, for example. This computational technique, known as voice conversion (VC), usually requires parallel data from two speakers to achieve a natural-sounding conversion. Parallel data requires recordings of two people saying the same sentences, with the necessary vocabulary, which are then time-matched and used to create a new target voice for the original speaker.
However, there are issues surrounding parallel data in speech processing, not least a need for exact matching vocabulary between two speakers, which leads to a lack of corpus for other vocabulary not included in the pre-defined model training. Now, Toru Nakashika at the University of Electro-Communications in Tokyo and co-workers have successfully created a model capable of using non-parallel data to create a target voice - in other words, the target voice can say sentences and vocabulary not used in model training.
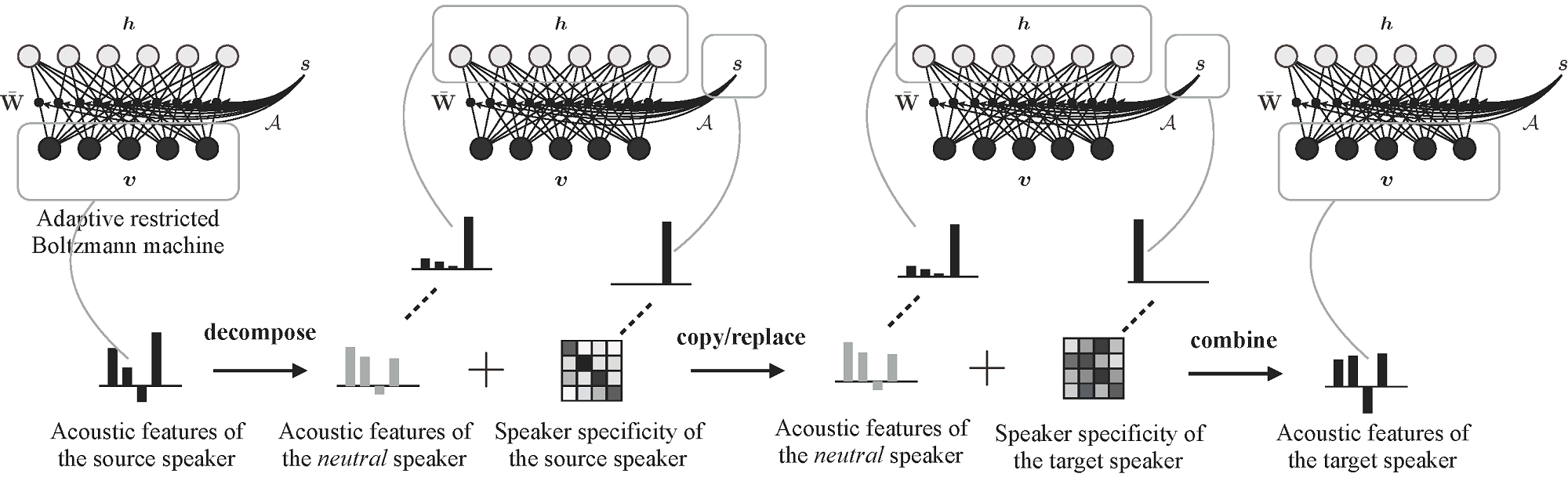
Their new VC method is based on the simple premise that the acoustic features of speech are made up of two layers - neutral phonological information belonging to no specific person, and 'speaker identity' features that make words sound like they are coming from a particular speaker. Nakashika's model, called an adaptive restricted Boltzmann machine, helps deconstruct speech, retaining the neutral phonological information but replacing speaker specific information with that of the target speaker.
After training, the model was comparable with existing parallel-trained models with the added advantage that new phonemic sounds can be generated for the target speaker, which enables speech generation of the target speaker with a different language.
Reference
- Nakashika, T., Takiguchi, T. & Minami, Y. Non-parallel training in voice conversion using an adaptive restricted Boltzmann machine. IEEE/ACM transactions on audio, speech and language processing 24 (11) (2016) DOI: 10.1109/TASLP.2016.2593263